Confusion Matrix(Hata Matrisi); sınıflandırma problemleri için kurulan modellerin performans değerlendirmesinde kullanılabilen bir ölçüt olarak ifade edebiliriz. Confusion Matrix · Hata Matrisi · Karmaşıklık Matrisi · Karışıklık Matrisi gibi çeşitli isimlendirmeler mevcuttur. Her ne olursa olsun sınıflandırma tahminleri şu dört değerlendirmeden birine sahip olacaktır.
- Doğruya doğru demek (True Positive – TP— Olumlu tahmin ettiniz ve bu DOĞRU)
- Yanlışa yanlış demek (True Negative – TN— Olumsuz tahmin ettiniz ve bu DOĞRU)
- Doğruya yanlış demek (False Positive – FP — Olumlu tahmin ettiniz ve bu YANLIŞ)
- Yanlışa doğru demek(False Negative – FN— Olumsuz tahmin ettiniz ve bu YANLIŞ)

- True Positive (TP): Hamile bir kadına hamilesin demek.
- True Negative (TN): Bir erkeğe hamile değilsin demek.
- False Positive (FP): Bir Erkeğe hamilesin demek.Tip 1 Hata (Hatalı Pozitif)
- False Negative (FN): Hamile olan bir kadına hamile değilsin demek.Tip 2 Hata (Hatalı Negatif)
Hamile olması imkansız olan birinin hamile olduğunu iddia etmek hatalı pozitiftir. Gerçekten de hamile bir kadının ultrasonuna bakıp da, doktor hatası nedeniyle hamile olmadığını iddia etmek ise tip 2 hatası olur.
Şimdi basit bir örnek ile devam edelim, hazır bir veri kullanalım:
import pandas as pd
# Gerekli kütüphane
from sklearn import metrics
# Basit bir liste
y_pred = [1,1,1,0,0,1,0,1,0,0,0,1,0,0,1,1,0,0,1,1,0,0,0,0,1,1,0]
y_test = [1,0,1,1,0,0,1,0,0,0,0,1,0,0,1,1,0,0,0,1,0,0,0,0,0,0,1]
# Python listemizi pandas series yapalım
y_pred = pd.Series(y_pred)
# Python listemizi pandas series yapalım
y_test = pd.Series(y_test)
# Hata matrisini oluşturalım
metrics.confusion_matrix(y_test, y_pred)
array([[12, 6],
[ 3, 6]])
Elde ettiğimiz hata matrisini daha iyi anlamak için aşağıda tablo üzerine tahminleri değerlendirelim:

- True Positive (TP): Hamile bir kadına hamilesin demek.
- True Negative (TN): Bir erkeğe hamile değilsin demek.
- False Positive (FP): Bir Erkeğe hamilesin demek.Tip 1 Hata (Hatalı Pozitif)
- False Negative (FN): Hamile olan bir kadına hamile değilsin demek.Tip 2 Hata (Hatalı Negatif)
Hata Matrisinden Elde Edilen Bazı Metrikler
Makine öğrenmesi algoritmalarının çalıştığımız veriler üzerinde ne kadar doğru tahmin yapabildiklerini ölçmek için çeşitli metriklere bakabiliriz. Bu metrikler: Accuracy, Error rate, Precision, Recall(Sensitivity), Specificity (Selectivity) ve F Score'dur.
Aşağıdaki resim başka bir bilimsel makaleden alınmış bazı algoritmaların sonuç değerlerini gösteren örnek bir tablodur, yukarıda ki verilerle bir ilişkisi yoktur. Aşağıdaki gibi bir tablodaki metriklerin başarılarına bakarak elinizdeki verilere en uygun modeli seçmek size kalmış.

Şimdi bu metrikler nasıl hesaplanır ve ne anlam ifade eder sırasıyla bakalım.
Doğruluk (Classification Accuracy-Accuracy skoru)
Accuracy, anlaşılması ve yorumlanması en basit ölçütlerden birisidir. Bu istatistik doğru tahmin oranıdır. Doğru tahmin oranı, etiketleri doğru tahmin edilen test gözlemlerinin toplam test gözlemlerinin sayısına bölünmesidir. Makine öğrenmesi sınıflandırma algoritmalarının testlerinde sıklıkla kullanılır. Accuracy skoru aşağıdaki gibi hesaplanır. Accuracy skoru 0 ve 1 arasında olup 1’e yaklaşan skorlarda model başarılı kabul edilir.
Dengesiz veri setlerinde accuracy yüksek çıkabilir, biz de çok iyi tahmin yaptık diye düşünebiliriz. Bu duruma accuracy paradox denir. Tahmin doğruluğunu gösteren bu metrik dengesiz veri setlerinde anlamsız olabilir. Recall ve precision değerleri önem kazanır. Yani, accuracy yüksek fakat recall veya precision düşük çıkıyorsa burada bir dengesizlik olabileceğini düşünmelisiniz!
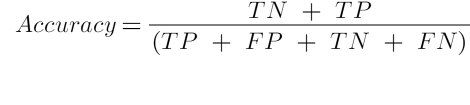
Accuracy(doğruluk), Python ile aşağıdaki gibi hesaplanabilir.
dogruluk = metrics.accuracy_score(y_test, y_pred)
#dogruluk
#0.66666666666666663
Hata Oranı (Error Rate / Misclassification Rate)
Genel olarak, sınıflayıcının ne sıklıkta yanlış tahmin ettiğinin bir ölçüsüdür. Hata Oranı olarak da bilinir (Error Rate).

Error Rate(Hata oranı), Python ile aşağıdaki gibi hesaplanabilir.
1 - metrics.accuracy_score(y_test, y_pred)
#0.33333333333333337
Precision(Kesinlik)
Tahmin ettiğim örnekler içerisinde gerçekten kaç tanesi doğru? sorusunun cevabıdır. Yani pozitif tahminlerin toplam pozitiflere oranı.
Hamile dediklerimizin gerçekten kaçı hamile?
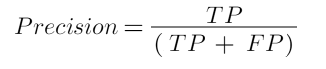
Precision(Kesinlik), Python ile aşağıdaki gibi hesaplanabilir.
metrics.precision_score(y_test, y_pred)
0.5
True Positive Rate(Duyarlılık, Sensitivity veya Recall)
Recall yada Sensitivity, sınıflar içerisinde doğru olduğu bilinen gözlemlerin doğru olarak tahmin edilenlerinin bütün doğru olduğu bilinen gözlemlere oranıdır. Pozitif sınıfa ait örneklerden kaç tanesini doğru tahmin ettim? sorusunun cevabıdır.
Hamile olanları doğru tespit etme oranımız.
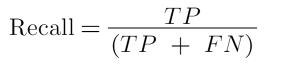
Recall, Python ile aşağıdaki gibi hesaplanabilir.
# Recall
print(metrics.recall_score(y_test, y_pred))
# ÇIKTI: 0.6666666666666666
False Positive Rate, Specificity (SPC), Selectivity, True negative rate (TNR)
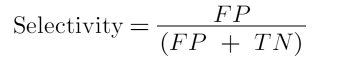
F Score
Modelin gücü, Precision ile Recall değerlerinin harmonik ortalamasıdır. Bu sebeple başarının iyi bir göstergesidir.
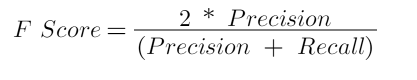
F Score, Python ile aşağıdaki gibi hesaplanabilir.
# F1-Score
print(metrics.f1_score(y_test, y_pred))
# ÇIKTI: 0.5714285714285715
Receiver Operating Characteristic (ROC)
Dengeli dağılım sahip veri setleri için kullanılabilecek bir diğer performans değerlendirme ölçütü ise ROC eğrisidir (Receiver Operator Characteristic Curve).

ROC CUNVEX HULL
Sınıflandırma Algoritmaları arasında karar vermek için ROC CUNVEX HULL kullanılabilir.

Confusion Matrix Python
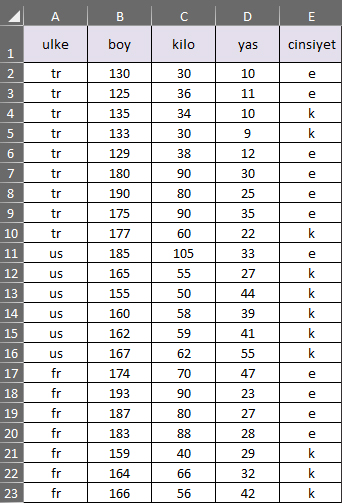
Şimdi ise aşağıdaki .csv dosyası içinde ülke, boy, kilo ve yaş verilerine göre cinsiyet tahmini yapabileceğimiz Python kodlama örneğine bakalım:
#1. kutuphaneler
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
veriler=pd.read_csv("veriler.csv")
#ulke,boy,kilo,yas,cinsiyet
x=veriler.iloc[:,1:4].values
y=veriler.iloc[:,4:].values
#Şimdi Train ve Test olarak ayırma işlemi yapalım
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.33,random_state=0)
#STANDARTLAŞTIRMA
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
X_train=sc.fit_transform(x_train)#fit_transform
X_test=sc.transform(x_test)#transform
#LOGISTIC REGRESSION
from sklearn.linear_model import LogisticRegression
log_r=LogisticRegression(random_state=0)
log_r.fit(X_train,y_train)#X den Y öğren
#şimdi öğrendiğin bilgi ile predict-tahmin yap
y_pred=log_r.predict(X_test)
print(y_pred)#tahnin sonuçları
print(y_test)#gerçek sonuçlar
#CONFUSION MATRİX-HATA MATRİSİ
from sklearn.metrics import confusion_matrix
cm=confusion_matrix(y_test,y_pred)
print(cm)
AUC
AUC'nin 1'e yaklaşması çok yüksek ayırt etme gücü anlamına gelir.
Heidke Skill Score (HSS)
Heidke Skill Score (HSS), bir sınıflandırma veya tahmin modelinin başarısını, rastgele tahmine göre ne kadar iyi olduğunu ölçen bir performans metriğidir. Özellikle meteoroloji, uzaktan algılama ve ikili sınıflandırma problemlerinde yaygın olarak kullanılır.
True Skill Statistic (TSS)
Dice Similarity Coefficient (DSC)
Segmentasyon çalışmalarında tahmin ve gerçek maskelerin örtüşmesini ölçer.
Intersection over Union (IoU) / Jaccard Index
Segmentasyon çalışmalarında kesişim alanının birleşim alanına oranı.
Kaynaklar
- https://www.miuul.com/not-defteri/dengesiz-veri-seti-ne-zaman-problem-olur
- https://www.youtube.com/watch?v=e8OXe9rBhr0&list=UULFL5JNqYlSVmoptUAUM23mow
- https://bernatas.medium.com/roc-e%C4%9Frisi-ve-e%C4%9Fri-alt%C4%B1nda-kalan-alan-auc-97b058e8e0cf
- https://www.mariakhalusova.com/posts/2019-04-17-ml-model-evaluation-metrics-p2/
- https://search.r-project.org/CRAN/refmans/qwraps2/html/confusion_matrix.html
- https://towardsai.net/p/l/multi-class-model-evaluation-with-confusion-matrix-and-classification-report
- https://www.mdpi.com/1999-4893/15/8/287#B43-algorithms-15-00287
- https://stephenallwright.com/micro-vs-macro-f1-score/
- https://www.mdpi.com/2075-4418/9/4/178#Author_Contributions (AUC)