Büyük hacimli veri setlerinde kayıp ya da eksik değerlerin bulunması sıkça karşılaşılan bir durumdur. Araştırmacıların elde ettiği verilerde, bazı nedenlerden dolayı eksik yada kayıp değerler olabiliyor. Veri setinin kalitesini yükseltmek için bu tür verilerin saptanması, veri setinden silinmesi ve bir takım yöntemlerle tamamlanması gerekir. Eksik verileri çıkarmanın sorun olabileceği durumlarda uygun veriler ile doldurmak için çeşitli yöntemler kullanabiliriz.
Aşağıda ki örnek veri üzerinden anlatmaya başlayabiliriz:
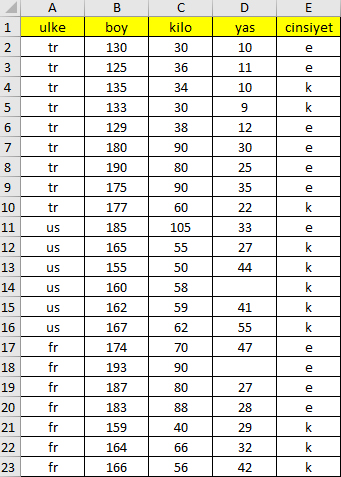
Veri Setinde Eksik Verileri Görmek
Öncelikle eksik veriler ile ilgili çeşitli bilgileri elde edebiliriz:
import pandas as pd
df = pd.read_csv("eksikveriler.csv", encoding='latin-1')
print(df.isnull().sum())
Eksik verileri yüzde olarak görebilmek için:
import pandas as pd
df = pd.read_csv("eksikveriler.csv", encoding='latin-1')
print(df.isnull().mean()*100)
Eksik Verileri Grafik Üzerinde Görmek
Eksik verileri grafik üzerinde görmek daha faydalı olabilir. Bunun için missingno paketini yüklememiz gerekir. Anaconda Prompt ekranında conda install -c conda-forge/label/gcc7 missingno kodunu çalıştırarak paketi kurabiliriz.
1- Matrix Grafik
import pandas as pd
import missingno as msno
df = pd.read_csv("eksikveriler.csv", encoding='latin-1')
msno.matrix(df.sample(len(df)))
Aşağıdaki matris görünümünde, eksik değerleri boş çizgilerle ve eksik olmayan değerleri siyah çizgilerle görebiliriz.

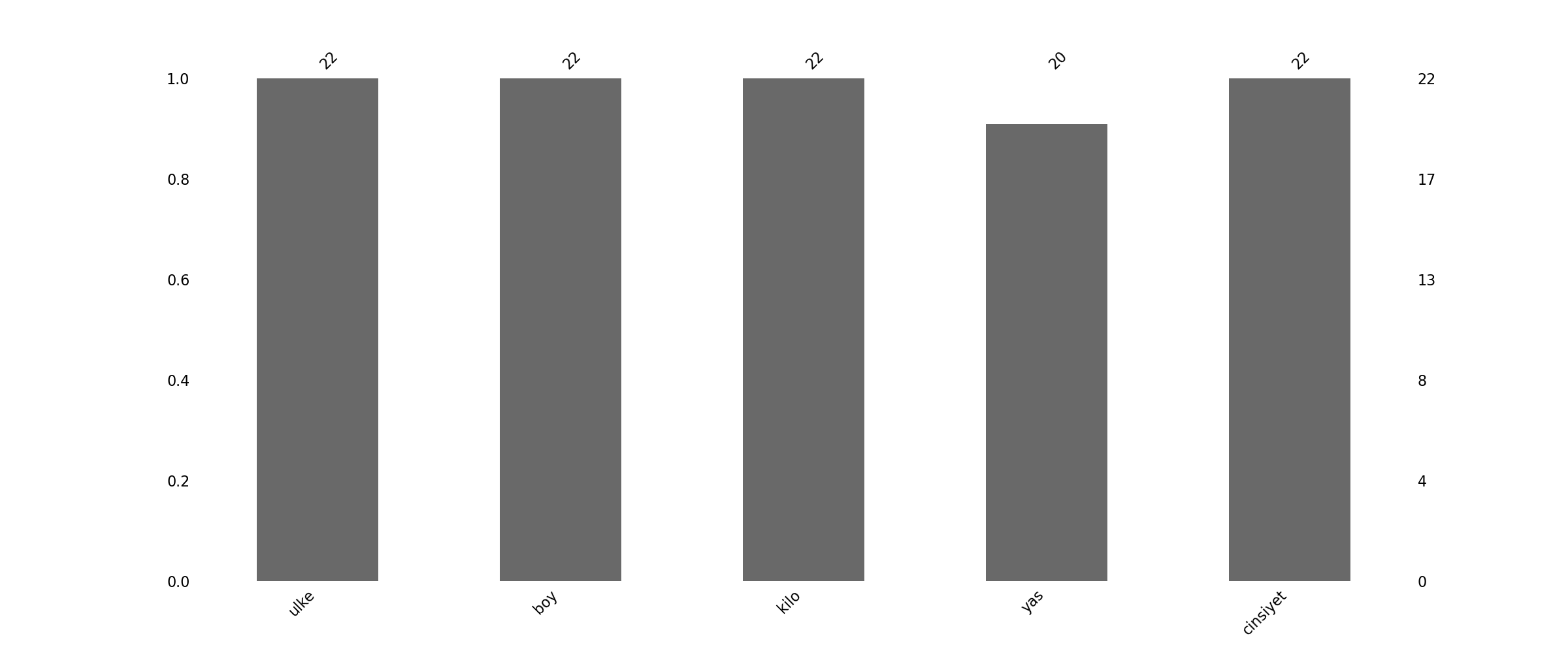
2- Bar Grafik
Ayrıca bar grafik olarak kullanmak için:
import pandas as pd
import missingno as msno
df = pd.read_csv("eksikveriler.csv", encoding='latin-1')
msno.bar(df)
Eksik Veri Olan Satırları Silme
DataFrame içinde eksik veri olan satırları silmek için aşağıdaki kodu kullanabiliriz:
import pandas as pd
df=pd.read_csv("eksikveriler.csv")
df.dropna(inplace=True)
print(df)
Eksik Verileri Tamamlama(Imputation) Yöntemleri
Bilimsel veriler içinde eksik veriler: (?, NaN) gibi ifadelerle gösterilir. Eksik veri tamamlama yöntemleri ile sayısal veriler üzerinde ya da sayısal olmayan(Nominal) veriler üzerinde çeşitli işlemler yapılabilir. Sayısal verilerde eksik veriler için kolonun ortalama değeri kullanılabilir. Sayısal olmayan veriler üzerinde imputer'in çalışma şansı yok.
- Merkezi ölçülerinin(ortalama, ortanca, medyan) ikamesi
- Yakın komşu merkezleri ile ikame(kNN)
- Regresyon eşitlikleri ile tahminleme
- Kukla değişkenler kullanma
- Hot deck imputation
- Cold deck imputation
- Beklenti Çoklaması-Expectation maximization (EM)
- Maximum likelihood(Maksimum Olabilirlik)
- Çoklu İmputasyon-Multiple imputations
- Bayesian analysis
1- Mean Substitution (Yerine Ortalamayı Koyma)
Bu yöntem ile veri setinde kayıp ya da eksik verilerin olduğu kolonun ortalaması alınır ardından eksik ya da kayıp olan veriler bu değer ile doldurulur. Mean ile eksik verilerin doldurulması bir yöntem dilerseniz en çok tekrar eden değeri yerleştirebilirsiniz, dışarıdan bir değeri atayabilirsiniz olmadı 0 yazabilirsiniz hatta bu satırı silebilirsiniz. Bu yöntem tamamen sizin veri setinize ve modelinize göre sizin karar vereceğiniz bir durumdur.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
veriler=pd.read_csv("eksikveriler.csv")
#print(veriler[['boy','kilo']])
#from sklearn.preprocessing import Imputer #was deprecated
from sklearn.impute import SimpleImputer
#missing_values:?,NaN
#strategy:mean(ortalama alma)
#axis:0 kolon bazlı ortalama
#imputer=Imputer(missing_values='NaN',strategy='mean',axis=0) #was deprecated
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
#1 dahil, 4 dahil değil(1,2,3.kolonları ayıralım)
sayisal_kolonlar=veriler.iloc[:,1:4].values
imputer=imputer.fit(sayisal_kolonlar[:,1:4])
sayisal_kolonlar[:,1:4]=imputer.transform(sayisal_kolonlar[:,1:4])
print(sayisal_kolonlar)
#nan değerleri yerine ortalama değer(28.45) yazılmıştır
SimpleImputer Imputation Strategy Parametreleri
Eksik değerin yerine "ortalama", "ortanca", "mod" ve istenilen "sabit bir değer" atanabilir.
#
# "Ortalama" ile eksik veri tamamlama
#
imputer = SimpleImputer(missing_values=np.NaN, strategy='mean')
#
# "Ortanca" ile eksik veri tamamlama
#
imputer = SimpleImputer(missing_values=np.NaN, strategy='median')
#
# En çok tekrar eden "Mod" ile eksik veri tamamlama
#
imputer = SimpleImputer(missing_values=np.NaN, strategy='most_frequent')
#
# Sabit bir değer ile eksik veri tamamlama, örn: 83
#
imputer = SimpleImputer(missing_values=np.NaN, strategy='constant', fill_value=83)
2- Knn Imputation
Kayıp değerleri hesaplamanın alternatif bir yolu da onları tahmin etmektir. En yakın komşu değer tahmini yaygın olarak kullanılmakta ve eksik değer tahmini için etkili bir yol olduğu bilinmektedir.
KNN Imputer sürekli, kesikli ve kategorik veri türleriyle çalışabilir ancak metin(string) verileriyle çalışamaz. Bu nedenle, verileri seçilen bir sütun alt kümesi ile filtreledik - boy, kilo ve yas. Ayrıca, bu sayısal verileri 0 ile 1 arasında normalleştirmek için scikit-learn'deki MinMaxScaler'ı kullandık. KNNImputer mesafe(distance) tabanlı bir algoritma olduğundan, ölçeklendirme işlemi önemli bir adımdır.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df=pd.read_csv("eksikveriler.csv")
# Imputing with KNNImputer
from sklearn.impute import KNNImputer
from sklearn.preprocessing import MinMaxScaler
#Define a subset of the dataset
df_knn = df.filter(['boy','kilo','yas'], axis=1).copy()
# Define scaler to set values between 0 and 1
scaler = MinMaxScaler(feature_range=(0, 1))
df_knn = pd.DataFrame(scaler.fit_transform(df_knn), columns = df_knn.columns)
# Define KNN imputer and fill missing values
knn_imputer = KNNImputer(n_neighbors=5, weights='uniform', metric='nan_euclidean')
df_knn_imputed = pd.DataFrame(knn_imputer.fit_transform(df_knn), columns=df_knn.columns)
print(df_knn_imputed)
Atanan ve orjinal değerlerin grafiğine göz atmak istersek:
fig = plt.Figure()
null_values = df['yas'].isnull()
fig = df_knn_imputed.plot(x='boy', y='kilo', kind='scatter', c=null_values, cmap='winter', title='KNN Imputation', colorbar=False)
Aşağıdaki resimde mavi noktalar var olan değerleri gösterirken yeşil olan noktalar yeni atanan değerleri göstermektedir.