Veriyi makine öğrenmesi algoritmalarına sokmadan önce, yani model için hazırlarken, veri üzerinde yapacağımız ön işlemlerden birisi de veri ölçekleme(feature scaling) işlemidir. Yöntemin amacı, nümerik veriler arasında farklılığın çok fazla olduğu durumlarda verileri daha dar bir aralığa sıkıştırmaktır.
Öncelikle bir örnek ile başlayalım; aşağıda ki örnek verilerde maaş aralıkları 1.000 ve katları iken tecrübe yılları 1 ve katları olarak ilerliyor.
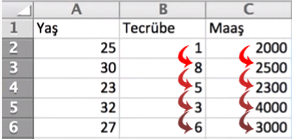
Eee.. ne var bunda? diyebilirsiniz ancak makine öğrenmesi algoritmaları bu verileri kendi aralarında hesaplarken büyük aralıklı değişkenlerin küçük aralıklı değişkenlerden daha önemli olduğunu düşünüyor! Dolayısıyla yanlı davranıp maaş değişkeninin daha önemli olduğunu düşünüp istatistiksel olarak taraflı davranıyor. Günün sonunda makine öğrenmesi algoritması bu sebeplerle iyi tahminler yapamayabilir. Bizim amacımız ise burada veriler arasında adaleti sağlamak olacak. Bu nedenle her iki kolondaki değerleri(tecrübe ve maaş) belirli bir aralığa sıkıştıracağız. Bunun için en çok bilinen 2 yöntem:

- Standartlaştırma Veri setindeki tüm verilerin ortalaması 0'a çekilir, standart sapma 1 olur.
- Normalleştirme Verileri min() ve max() değerlere göre (0-1) aralığına sıkıştırır. Yani en düşük maaş artık 0 olurken en yüksek maaş +1 olur. Yine en küçük tecrübe 0 olurken en yüksek tecrübe +1 olur.
Feature scaling'e neden ihtiyaç duyulur?
- Veri ölçeklendirme ile bazı modellerde daha iyi performans gözlendiği ve daha iyi sonuçlar elde edildiği için,
- Hesaplama sırasında bazı sayısal zorluklardan kaçınmak için,
Hangi Algoritmalarda Feature Scaling Kullanılması Gerekir?
Özellikle uzaklık temelli algoritmaların sonucunu etkilerken, gradient descent kullanan algoritmaların hızını etkilemektedir.
- KNN
- SVM
- K_Means
- Yapay Sinir Ağları
- Gradient Descent kullanan algoritmalar
Feature Scaling diğer bir ifadeyle Min-Max Normalization olarak da bilinir. İstatistikte birbirinden çok farklı büyüklükteki sayıların birbiri ile ilişkilendirilmesi ya da birbiri arasında hesaplamalar yapılabilmesi için kullanılan yöntemlere normalizasyon deniliyor.
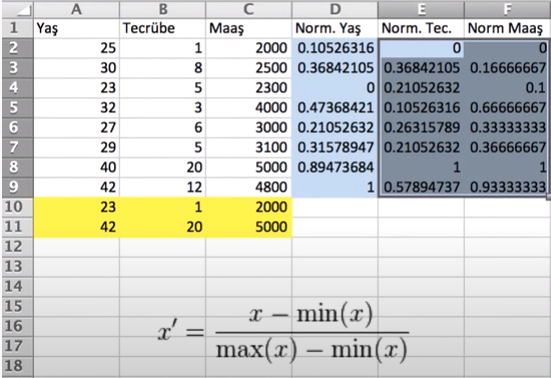
Yukarıda ki örnek verilerde maaş aralıkları 1.000 ve katları iken tecrübe yılları 1 ve katları olarak ilerliyor. Bu verilerin hepsini 0-1 aralığına almak için verilerin min ve max değerleri hesaplanıp normalizasyon formülünde yerlerine konularak istenilen veriler elde edilir. Yukarıda ki resimde sağdaki renkli alanlar normalize edilmiş verilerdir. Örnek olarak bu videoya bakabilirsiniz.
- Standartlaştırma Daha iyi sonuçlar verir, aşırı büyük değerler olsa dahi farklılık çok kaybolmaz, tercih edilir.
- Normalleştirme (0-1 arası) Outline yani aşırı büyük değerler varsa farklılık kaybolur, bütün değerler sıfıra yaklaşır ve işe yaramaz.
Python scikit learn kütüphanesi kullanarak bu işlemleri nasıl yaparız.
Standartlaştırma
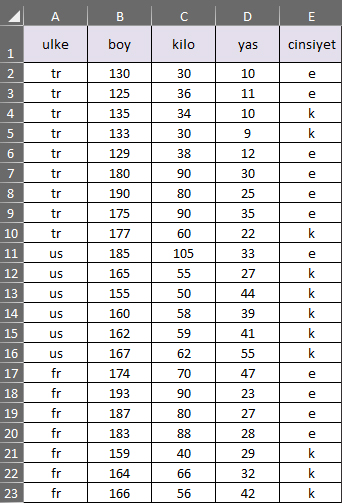
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
veriler= pd.read_csv("veriler.csv")
#ülke kolonu one hot encoding yapılıyor
ulke=veriler.iloc[:,0:1]#ilk kolonu alır
from sklearn.preprocessing import OneHotEncoder
ohe=OneHotEncoder(categorical_features='all')
#kolonu fit transformdan geçirip geri kolona yazsın
ulke=ohe.fit_transform(ulke).toarray()
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
ulke_df=pd.DataFrame(data=ulke,index=range(22),columns=['fr','tr','us'])
#print(ulke_df)
#sayisal kolonlar
sayisal_kolonlar=veriler.iloc[:,1:4].values
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
sayisal_kolonlar_df=pd.DataFrame(data=sayisal_kolonlar,index=range(22),columns=['boy','kilo','yas'])
#print(sayisal_kolonlar_df)
#cinsiyet
cinsiyet=veriler.iloc[:,4:5]#4 ile 5.kolon arası, 5.kolon dahil değil
#numpy array den dataFrame yapma(index ve kolon başlıkları eklenir)
cinsiyet_df=pd.DataFrame(data=cinsiyet,index=range(22),columns=['cinsiyet'])
#print(cinsiyet_df)
#BİRLEŞTİRME-CONCAT(DataFrame ler birleştirilir)
#Veriyi Geri Birleştirme, iki veri birleştirme
ulke_sayisal_kolanlar_concat=pd.concat([ulke_df,sayisal_kolonlar_df],axis=1)#axis=1 yanyana birleştirir
#TEST VE TRAIN VERİLERİ BÖLME
#ulke_sayisal_kolanlar_concat değişkeni içnde ülke,boy,kilo ve yaş kolonları var cinsiyet kolonu yok
#cinsiyet kolonu bağımlı değişken, diğer kolonlar ise bağımsız değişkenler
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(ulke_sayisal_kolanlar_concat,cinsiyet,test_size=0.33,random_state=0)
#STANDARTLAŞTIRMA
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
x_train=sc.fit_transform(x_train)
x_test=sc.fit_transform(x_test)
Ortalama değer sıfıra çekmeye çalışılır.