Random Forest Algoritması hem sınıflandırma hemde regresyon(tahmin) için kullanılabilen, (Breiman, 2001) tarafından aşırı uyum sorununa çözüm bulmak için geliştirilmiş, çeşitli karar ağacı modellerinin birleştirilmesi ya da toplulaştırılmasına dayanan popüler bir toplulaştırma tekniğidir (Cebeci, 2022). Amaç veri kümesini birden fazla parçaya bölmek ve bunlar üzerinde karar ağaçlarını çalıştırıp daha sonra birleştirmek.
Temel olarak, birden fazla karar ağacının tahminlerini birleştirerek daha doğru ve kararlı bir tahmin sağlar. Random Forest algoritması, aşağıdaki durumlarda kullanılabilir:
- Özellikler arasında karmaşık etkileşimler bulunan veri kümesi durumlarında: Random Forest, özellikler arasındaki etkileşimleri otomatik olarak yakalayabilen ve modelin doğruluğunu artıran bir algoritmadır.
- Hem kategorik hem de sürekli özelliklere sahip veri kümelerinde: Random Forest algoritması, kategorik ve sürekli özelliklerin her ikisiyle de başa çıkabilen çok yönlü bir algoritmadır.
- Yüksek boyutlu veri kümelerinde: Random Forest, yüksek boyutlu veri kümelerini işlemekte etkilidir ve önemli özellikleri belirleyebilir.
- Aşırı öğrenmeye karşı dayanıklılık gerektiren durumlarda: Random Forest algoritması, birden fazla karar ağacının tahminlerini birleştirerek aşırı öğrenmeye karşı dayanıklılık sağlar.
- Özellik seçimi ve öneminin değerlendirilmesi gereken durumlarda: Random Forest, özellik önemini ölçmekte ve önemsiz özelliklerin etkisini azaltmakta etkilidir.
- Hızlı tahmin yapma gereksinimi olan durumlarda: Random Forest, paralel olarak çalışabilen ve hızlı tahminler yapabilen bir algoritmadır.
- Modelin yorumlanabilirliği önemli olmayan durumlarda: Random Forest algoritması, doğru ve kararlı tahminler sağlasa da, modelin yorumlanabilirliği daha düşüktür. Eğer modelin yorumlanabilirliği önemli değilse, Random Forest algoritması kullanılabilir.
Random Forest algoritması, çok çeşitli uygulama alanlarında kullanılabilir, ancak her durumda en iyi seçenek olmayabilir. Problemin doğasına ve veri kümesine bağlı olarak, başka makine öğrenmesi algoritmaları daha uygun olabilir. Bu nedenle, en iyi modeli belirlemek için çapraz doğrulama ve hiperparametre ayarlama gibi teknikler kullanarak birden fazla algoritmayı denemekte fayda vardır.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
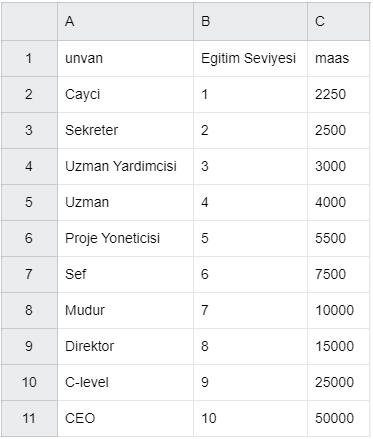
veriler= pd.read_csv("maaslar.csv")
x=veriler.iloc[:,1:2]#eğitim seviyesi
y=veriler.iloc[:,2:]#maaş
X=x.values
Y=y.values
#TEST VE TRAIN VERİLERİ BÖLME
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.33,random_state=0)
#STANDARTLAŞTIRMA
from sklearn.preprocessing import StandardScaler
sc1=StandardScaler()
x_olcekli=sc1.fit_transform(X)
sc2=StandardScaler()
y_olcekli=sc2.fit_transform(Y)
#RANDOM FOREST
from sklearn.ensemble import RandomForestRegressor
rf_reg=RandomForestRegressor(n_estimators=10,random_state=0)
rf_reg.fit(X,Y)#X bilgisinden Y bilgisini öğren
print(rf_reg.predict(np.array([6.5]).reshape(1, 1)))
plt.scatter(X,Y,color='red')
plt.plot(x,rf_reg.predict(X),color='blue')
plt.show()
Rastgele Orman, hem sınıflandırma hem de regresyon için kullanılan bir topluluk makine öğrenme algoritmasıdır. Tek bir karar ağacına güvenmek yerine, birden fazla ağaç oluşturur ve tahminlerini birleştirir. Her ağaç, verilerin ve özelliklerin rastgele bir alt kümesi üzerinde eğitilir. Bir tahmin yapıldığında, tüm ağaçlar nihai sonuç için oy kullanır.
Kaynaklar
- https://link.springer.com/article/10.1023/A:1010933404324 (Breiman, 2001)
- Cebeci, Z., Tekeli, E., & Tahtalı, Y. (2022). Tarım, gıda ve yaşam bilimlerinde R ile makine öğrenmesi ve veri madenciliği. Nobel Akademik Yayıncılık.
- https://link.springer.com/article/10.1023/a:1010933404324
- https://www.instagram.com/reels/DVflaBQD7NR/
- https://link.springer.com/article/10.1023/a:1010933404324 (atıf olarak kullanılabilir)
- https://www.mdpi.com/2072-4292/9/4/309