import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
veriler=pd.read_csv('maaslar_yeni.csv')
#Calisan ID,unvan,UnvanSeviyesi,Kidem,Puan,maas
#10 yıl tecrübeli 100 puan almış bie CEO ve aynı özelliklere sahip bir müdürün
#maşlarını 5 farklı yöntemle hesaplayınız.
#Öncelikle kolonlarda ki ID değerini almıyoruz! gerek yok
#unvanSeviyesi olduğu için unvan kolonunu almaya gerek yok-dummy variable(kukla değişken) olmasın!
#unvanSeviyesi kolonu olmasaydı belki ünvan kolonlarında labelEncoding yapılabilirdi.
#unvanseviyesi,kıdem ve puan sayısal değişkenler ve bunları kullanarak maaş tahmini yapacağız
#unvaseviyesi, kıdem ve maaş bunlar bağımsız değşiken ,
#bunları kullanarak bağımlı değişken olan maaş tahmini yapacağız
x=veriler.iloc[:,2:5]#2 ile 5 kolonu arası-5 dahil değil, unvanseviyesi,kıdem,puan
y=veriler.iloc[:,5]#maaş, 5 den sonraki kolon
X=x.values#numpy array şeklinde
Y=y.values#numpy array şeklinde, kolon başlıkları ve index sıralama yok
# unvanseviyesi,kıdem,puan değişkenleri hesaplamaya gerçekten etki ediyorlar mı
# bunun için p-value değerine bakacağız.p-value den önce linear regression yapalım:
#1.0-MULTI LINEAR REGRESSION
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,Y)#X'den Y öğren
#1.1-BACKWARD ELIMINATION
import statsmodels.api as sm
#X=np.append(arr=np.ones((22,1)).astype(int), values=veri, axis=1)
regressor_OLS = sm.OLS(endog = lin_reg.predict(X), exog = X).fit()
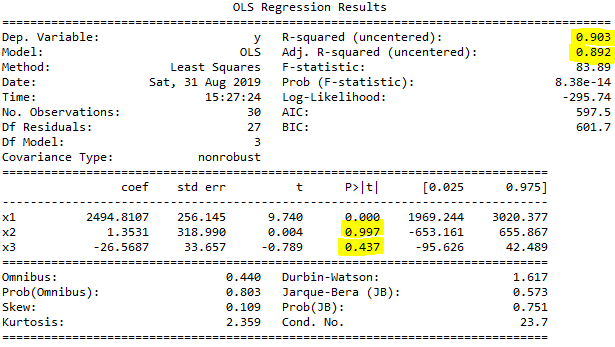
print(regressor_OLS.summary())
Print sonucu P-value ve R2 değerine baktığımızda iki değişkenin p-value değerleri 0,5 den büyük olduğu için bu değişkenleri hesaplamaya katmayacağız. Ayrıca R2 değeri 1'e yakın güzel fakat bu gereksiz değişkenleri çıkarıp hesapladıktan sonra 1'e daha yakın bir değer çıkmasını bekliyoruz.
Şimdi x2 ve x3 değişkenlerini almadan tekrar hesap edelim.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
veriler=pd.read_csv('maaslar_yeni.csv')
#Calisan ID,unvan,UnvanSeviyesi,Kidem,Puan,maas
#10 yıl tecrübeli 100 puan almış bie CEO ve aynı özelliklere sahip bir müdürün
#maşlarını 5 farklı yöntemle hesaplayınız.
#♥daha önceden p-value değerlerine bakarak kıdem ve puan kolonlarını çıkardık
x=veriler.iloc[:,2:3]#2 ile 3 kolonu arası-3 dahil değil, unvanseviyesi
y=veriler.iloc[:,5]#maaş, 5 den sonraki kolon
X=x.values#numpy array şeklinde
Y=y.values#numpy array şeklinde, kolon başlıkları ve index sıralama yok
#1.0-MULTI LINEAR REGRESSION
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,Y)#X'den Y öğren
#1.1-BACKWARD ELIMINATION
import statsmodels.api as sm
#X=np.append(arr=np.ones((22,1)).astype(int), values=veri, axis=1)
regressor_OLS = sm.OLS(endog = lin_reg.predict(X), exog = X).fit()
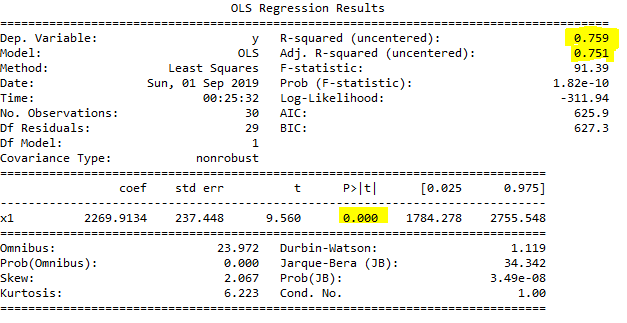
print(regressor_OLS.summary())

Gördüğümüz gibi p-value değeri artık 0,5'den küçük ve R2 değeri 1'e daha yaklaştı. Sadece ünvan seviyesi kolonunu kullanarak hesaplama yapabiliriz.
#2.0-POLINOM REGRESSION
from sklearn.preprocessing import PolynomialFeatures
poly_reg=PolynomialFeatures(degree=4)#polinom derecesini belirtebiliriz
#multiple linear regression da kullanmak üzere x_poly kolonu üretiyoruz
x_poly=poly_reg.fit_transform(X)
poly_reg.fit(x_poly,Y)#fit etmek eğitmek demek
#üretilen x_poly değerini linear regression da kullanalım
pol_lin_reg=LinearRegression()
pol_lin_reg.fit(x_poly,y)
#2.1-BACKWARD ELIMINATION
poly_reg_OLS = sm.OLS(endog = pol_lin_reg.predict(x_poly), exog = X).fit()
print(poly_reg_OLS.summary())
#3.0-SVR
#SVR yapılırken verinin mutlaka ölçeklendirilmesi gerekir
#STANDARTLAŞTIRMA
from sklearn.preprocessing import StandardScaler
scx=StandardScaler()
x_olcekli=scx.fit_transform(X)
scy=StandardScaler()
y_olcekli=scy.fit_transform(Y)
from sklearn.svm import SVR
svr_reg=SVR(kernel='rbf')
svr_reg.fit(x_olcekli,y_olcekli)
#3.1-BACKWARD ELIMINATION
svr_reg_OLS = sm.OLS(endog = svr_reg.predict(x_olcekli), exog = x_olcekli).fit()
print(svr_reg_OLS.summary())
#4.0-DECISION TREE
from sklearn.tree import DecisionTreeRegressor
r_dt=DecisionTreeRegressor(random_state=0)
r_dt.fit(X,Y)#X kullanarak Y öğren
#4.1-BACKWARD ELIMINATION
r_dt_OLS = sm.OLS(endog = r_dt.predict(X), exog = X).fit()
print(r_dt_OLS.summary())
#5.0-RANDOM FOREST
from sklearn.ensemble import RandomForestRegressor
rf_reg=RandomForestRegressor(n_estimators=10,random_state=0)
rf_reg.fit(X,Y)#X bilgisinden Y bilgisini öğren
#5.1-BACKWARD ELIMINATION
rf_reg_OLS = sm.OLS(rf_reg.predict(X),X).fit()
print(rf_reg_OLS.summary())
1 parametreli
Linear :
R-squared (uncentered): 0.942
Polinom:
R-squared (uncentered): 0.759
SVR:
R-squared (uncentered): 0.770
Decision Tree:
R-squared (uncentered): 0.751
Random Forest:
R-squared (uncentered): 0.719
3 parametreli
Linear :
R-squared (uncentered): 0.903
Polinom:
R-squared (uncentered): 0.680
SVR:
R-squared (uncentered): 0.782
Decision Tree:
R-squared (uncentered): 0.679
Random Forest:
R-squared (uncentered): 0.713