Makine öğrenmesinde, özelliklerin(feature) önem puanları, bir tahmin modeli oluştururken bir veri kümesindeki her bir özelliğin göreceli önemini belirlemek için kullanılır. Bu puanlar, karar ağaçları, rastgele ormanlar, doğrusal modeller ve sinir ağları gibi çeşitli teknikler kullanılarak hesaplanır.
Bir veri setinde hangi kolonların ne kadar önemli olduklarını(feature importance) anlamak için Random Forest kullanabiliriz. Aşağıda İris veri seti üzerinden bunu nasıl yaptığımızı görebilirsiniz:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 1. Veri setini yükleyin
# Örneğin: iris veri seti
from sklearn.datasets import load_iris
data = load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
df['target'] = data.target
# 2. Özellikler (X) ve hedef (y) değişkeni
X = df.drop(columns=['target'])
y = df['target']
# 3. Eğitim ve test setlerine bölme
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. Random Forest Modelini Eğitme
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 5. Özellik önemlerini alma
feature_importances = model.feature_importances_
# 6. Özellik önemlerini görselleştirme
plt.figure(figsize=(10, 6))
plt.barh(X.columns, feature_importances, color='turquoise')
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance Using Random Forest")
plt.show()

from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import pandas as pd
# CSV dosyasını okuma ve ilk satırı sütun isimleri olarak ayarlama
df = pd.read_csv("https://bilisimkitabi.com/files/kimyasal_bilesenler_dummy.csv", header=0)
# Özellikler (X) ve hedef değişkeni (y) belirleme
X = df.drop(columns=['HarvestTime'])
y = df['HarvestTime']
# Modeli oluştur ve eğit
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X, y)
# Özellik önemlerini al
importances = clf.feature_importances_
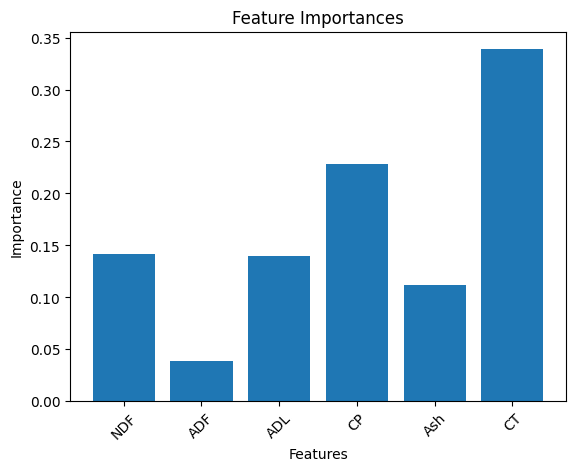
# Özelliklerin önemini yazdır
for feature, importance in zip(X.columns, importances):
print(f"{feature}: {importance:.4f}")
# Özellik önemlerini görselleştir
plt.bar(X.columns, importances)
plt.xlabel('Features')
plt.ylabel('Importance')
plt.title('Feature Importances')
plt.xticks(rotation=45)
plt.show()
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 1. Veri setini yükleyin
df = pd.read_csv("https://bilisimkitabi.com/files/kimyasal_bilesenler_dummy.csv", header=0)
# 2. Özellikler (X) ve hedef (y) değişkeni
X = df.drop(columns=['HarvestTime'])
y = df['HarvestTime']
# 3. Eğitim ve test setlerine bölme
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 4. Random Forest Modelini Eğitme
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 5. Özellik önemlerini alma
feature_importances = model.feature_importances_
# 6. Özellik önemlerini görselleştirme
plt.figure(figsize=(10, 6))
plt.barh(X.columns, feature_importances, color='turquoise')
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance Using Random Forest")
plt.show()

Özellik seçimi: En önemli özellikleri belirleyerek, uygulayıcılar bir model oluşturmada kullanılacak ilgili özelliklerin bir alt kümesini seçebilir, verilerdeki boyutluluğu ve gürültüyü azaltabilir ve model yorumlanabilirliğini iyileştirebilir.
Model yorumlanabilirliği: Hangi özelliklerin en önemli olduğunu anlayarak, uygulayıcılar verilerdeki temel ilişkiler ve modelin nasıl tahminler yaptığı hakkında fikir edinebilirler.
Model hata ayıklama: Bir model iyi performans göstermiyorsa, özellik önemi hangi özelliklerin sorunlara neden olabileceğini ve daha fazla araştırma gerektirebileceğini belirlemek için kullanılabilir.
İş karar alma: Hangi özelliklerin en önemli olduğunu anlayarak, uygulayıcılar hangi özelliklerin toplanacağı ve kaynakların nasıl tahsis edileceği konusunda daha bilinçli kararlar alabilirler.
Model performansını iyileştirme: Daha az önemli özellikleri kaldırarak, uygulayıcılar aşırı uyumu ve eğitim süresini azaltarak model performansını iyileştirebilir.
Eksik Veri Varsa Feature Importance Yapılır mı?
Yukarıdaki veri setlerinde eksik veri yoktu onun için bir hata almadan çalıştırabildik ancak eksik veriler varsa iki yaklaşım ile hata almadan çıktı alabiliriz:
- Eksik veri varsa, silmek
- Eksik veri varsa, tamamlamamak
Eksik Verileri Silmek
df.dropna(inplace=True)
Eksik Verileri Doldurmak (Tamamlamak)
df.fillna(df.mean(numeric_only=True), inplace=True)
df.fillna("Bilinmiyor", inplace=True)
Pipeline ile
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
# 1. Veri yükleme
df = pd.read_excel("data.xlsx")
# 2. Hedef ve özellikler
X = df.drop("HASTA", axis=1)
y = df["HASTA"]
# 3. Sayısal ve kategorik sütunları ayır
num_cols = X.select_dtypes(include=['int64', 'float64']).columns
cat_cols = X.select_dtypes(include=['object']).columns
# 4. Ön işleme pipeline
numeric_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="mean"))
])
categorical_transformer = Pipeline(steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("encoder", OneHotEncoder(handle_unknown="ignore"))
])
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, num_cols),
("cat", categorical_transformer, cat_cols)
]
)
# 5. Model pipeline
model = Pipeline(steps=[
("preprocess", preprocessor),
("rf", RandomForestClassifier(random_state=42))
])
# 6. Train-test split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 7. Model eğitimi
model.fit(X_train, y_train)
# 8. Feature importance alma
rf_model = model.named_steps["rf"]
# One-hot sonrası feature isimlerini al
ohe = model.named_steps["preprocess"].named_transformers_["cat"].named_steps["encoder"]
cat_feature_names = ohe.get_feature_names_out(cat_cols)
all_feature_names = np.concatenate([num_cols, cat_feature_names])
importances = rf_model.feature_importances_
# 9. DataFrame oluştur (sıralı)
feat_imp_df = pd.DataFrame({
"Feature": all_feature_names,
"Importance": importances
}).sort_values(by="Importance", ascending=True)
# 10. Görselleştirme
plt.figure(figsize=(10, 8))
plt.barh(feat_imp_df["Feature"], feat_imp_df["Importance"], color="turquoise")
plt.xlabel("Feature Importance")
plt.ylabel("Features")
plt.title("Feature Importance (Random Forest)")
plt.tight_layout()
plt.show()